Facebook Messenger Chatbot
Spring 2018 — PyTorch project
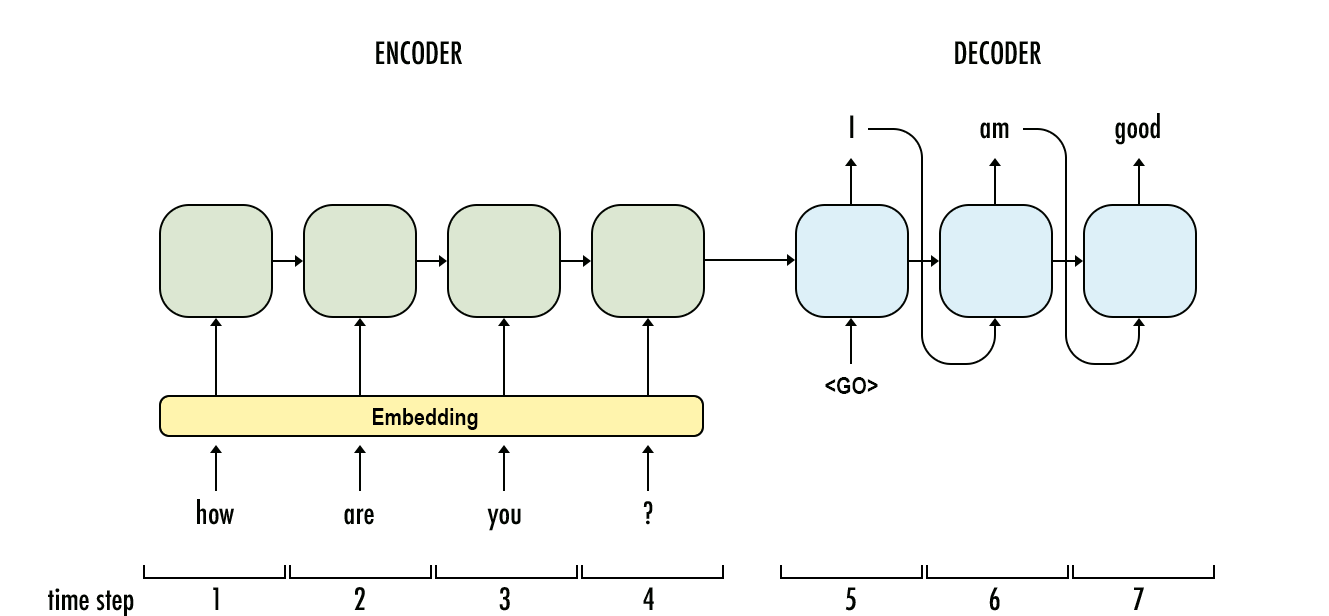
After working with sequence to sequence models for image captioning in the semester prior, I examined how they performed when applied to chat data. The goal was to train a model to respond to input text, mimicking how users respond in Facebook Messenger chat data. I was also curious how much an out-of-the-box seq2seq model could learn from the chat data — how unique is a single person’s style of messaging, and how well could a model learn patterns across messages, as opposed to a language model trained on single messages?
I used data downloaded from my old Facebook account, and anonymized all users except for myself. I then trained the model on all (message, response) pairs where I authored the response. Using the trained model, I wrote a REPL where users can interact with the chatbot.
One issue that arose was a matter of sampling from the trained model. Since there wasn’t that much data, even when using pre-trained word embeddings, randomly sampling the model usually generated nonsensical responses. On the other end of the sampling spectrum, selecting the highest probability response yielded low variation in responses (many of the responses were “I mean, I’m not sure.”). To strike a compromise between the sampling methods, I randomly alternated between the two.
Future work may involve using attention on the input phrase, as well as word dropout for regularization. The latter feature may improve coherence of responses more than the current approach.
The model and REPL code are on GitHub. Note that I didn’t include the training data nor trained model parameters out of respect for the privacy of my friends and myself.