Answering questions with a pretrained, non-fine-tuned BERT language model
Spring 2023 — PyTorch project

Overview
In this project, I explored the potential to use an unmodified pretrained BERT language model to answer questions. This project was motiviated by two ideas:
Questions answering can be rephrased as a fill-in-the-blank task, which is similar to how BERT models are trained.
Given a reference paragraph, if we mask out a word or phrase, then BERT will try to fill in the masked section using the surrounding text as context clues. In other words, BERT uses the context to predict masked tokens.
Both cases are fill-in-the-blank tasks which BERT is capable of solving. Our hypothesis is as follows: given the same entity, if described in a declarative sentence or a question turned into a sentence, BERT should output roughly the same predictions in both cases.
Example
Here’s an example: suppose we have the sentence “John threw the frisbee to the dog”. If we have the question, “Who threw the frisbee?”, we can convert it into the masked sentence, “[MASK] threw the frisbee”. Similarly, if we mask the token “John” from the sentence, we have the sentence “[MASK] threw the frisbee to the dog.”
If we feed in both masked sentence to BERT, the output token probabilities for both [MASK] tokens should be similar. If we mask out “dog” instead of “John”, and look at the probabilities for “John threw the frisbee to [MASK]”, the resulting token probabilities would not be as similar to the probabilities for the masked token in “[MASK] threw the frisbee”.
Similiarly, if we have the question “To whom was the frisbee thrown?” and we convert it to the masked sentence “The frisbee was thrown to [MASK]”, then the resulting probabilities will match the masked token predictions for the sentence “John threw the frisbee to [MASK]” more closely than those for the sentence “[MASK] threw the frisbee to the dog.”
Essentially, we can convert the problem of question answering to a fill-in-the-blank task, and the resulting task becomes a matter of finding the word or phrase in the sentence to mask that will most closely match the masked question-turned-sentence probabilities.
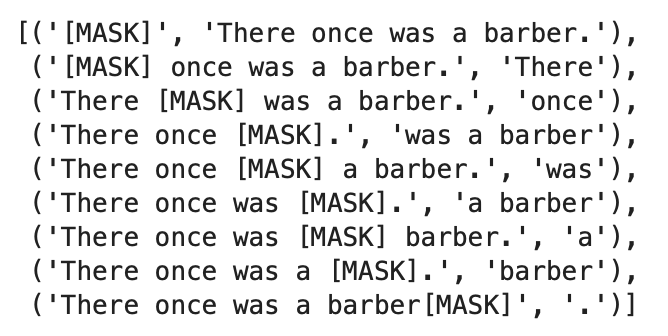
Benefits of this approach
One main benefit of the approach is that it doesn’t rely too much on BERT’s biases. Since we mask out the answer candidates from the input context, BERT never actually sees what the answer candidates are, it only knows what tokens it thinks are likely to take the answer candidates’ place. This means that when considering answers, BERT doesn’t use its biases about the answers themselves when considering if they answer the question - it solely uses the context for each answer.
In other words, when considering the sentence, “Mary played with Beth”, when we mask out “Mary” and ask BERT to predict the masked token for the sentence “[MASK] played with Beth”, BERT represents the token as “they who played with Beth”. Then, when we have the question, “Who played with Beth”, the BERT model has seen a masked token with a representation of “they who played with Beth”, so it knows that the masked token is a good answer candidate.
Another benefit to this approach is that it uses a pretrained out-of-the-box BERT model, we don’t need to do any extra training or fine-tuning (which can be expensive for large models or large training sets).
Drawbacks
This approach is a bit hacky, in that not all answers are single words. However, assuming the BERT model tokens are tokenized by full words, we use BERT as if we’re expecting single word answers. For more complicated answers to questions, BERT might predict short, generic words like “it”, “she”, “he”, without incorporating information about the true answer in the output probabilities. One way to mitigate this problem would be to train a BERT model for this exact task, so that the output likelihoods of the correct masked answers will be trained to match the target likelihood distribution for the training questions.
The other drawback is that this model can only answer factoid questions that have answers directly in the text. More general questions that require some reasoning or inference wouldn’t work well with this model — many times the answer to those questions can’t be directly pulled from text. Since this model necessarily only considers answers from input text, any question with an answer not directly in the text cannot be answered by this model.
Using parse trees to generate all answer candidates
In order to mask out all possible answer candidates, we can use a syntax parse of the input sentence, and iteratively mask out all words and phrases one-by-one. We treat each masked sentence as an answer candidate, with the answer being the masked text, and we feed each sentence into BERT to get the output probabilities. Then, we compare the output probabilities with the probabilities with the probabilties from the target masked sentence. For now, we manually convert questions into sentences.
Comparing output distributions
We simplify the output distribution comparison step by instead comparing the output BERT embeddings. We test our model using cosine similarity and euclidean distance to measure how closely an answer candidate output embedding matches a target output embedding.
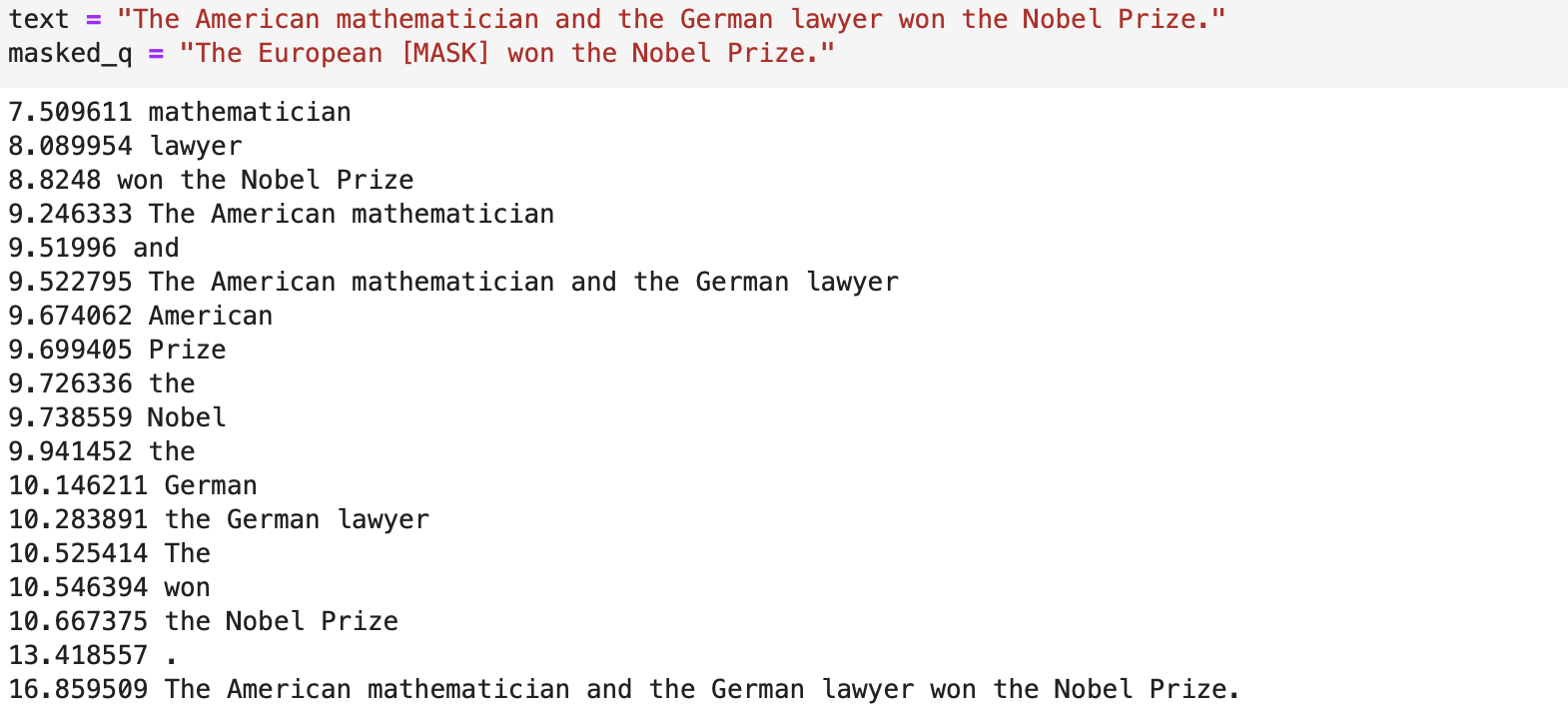
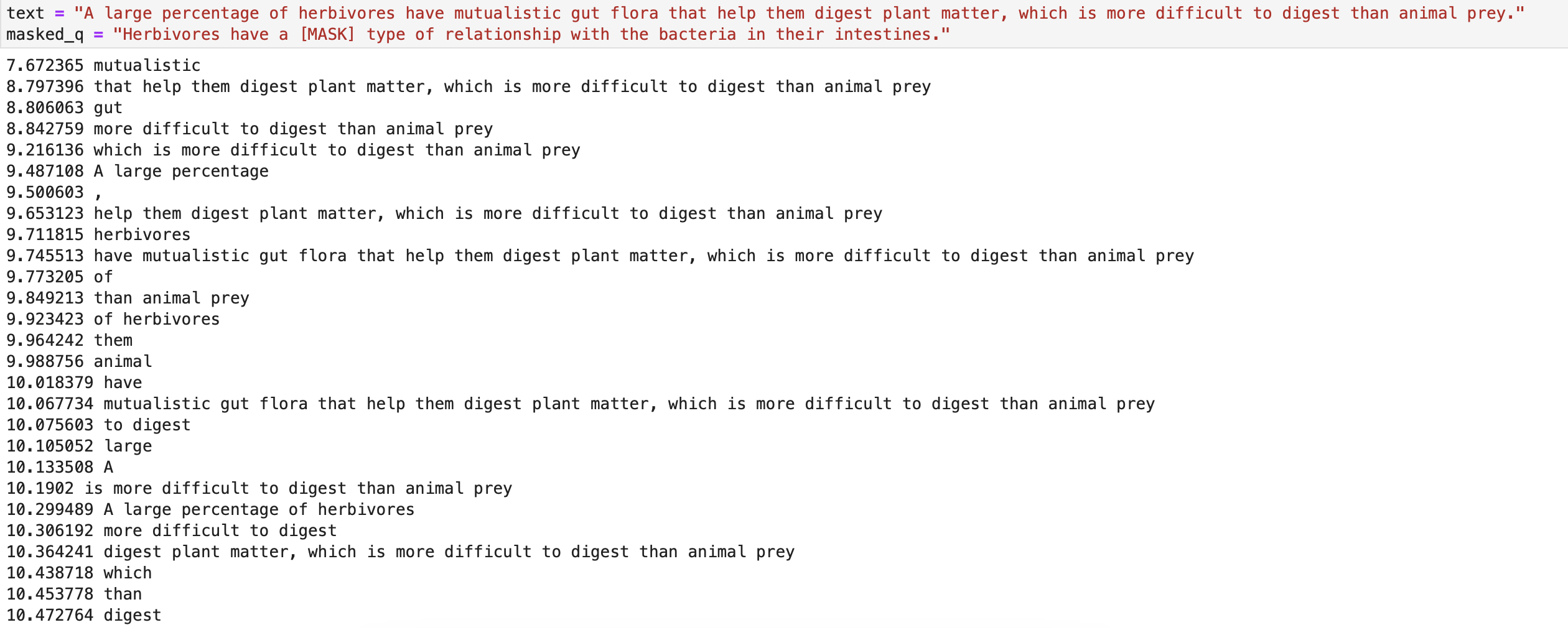
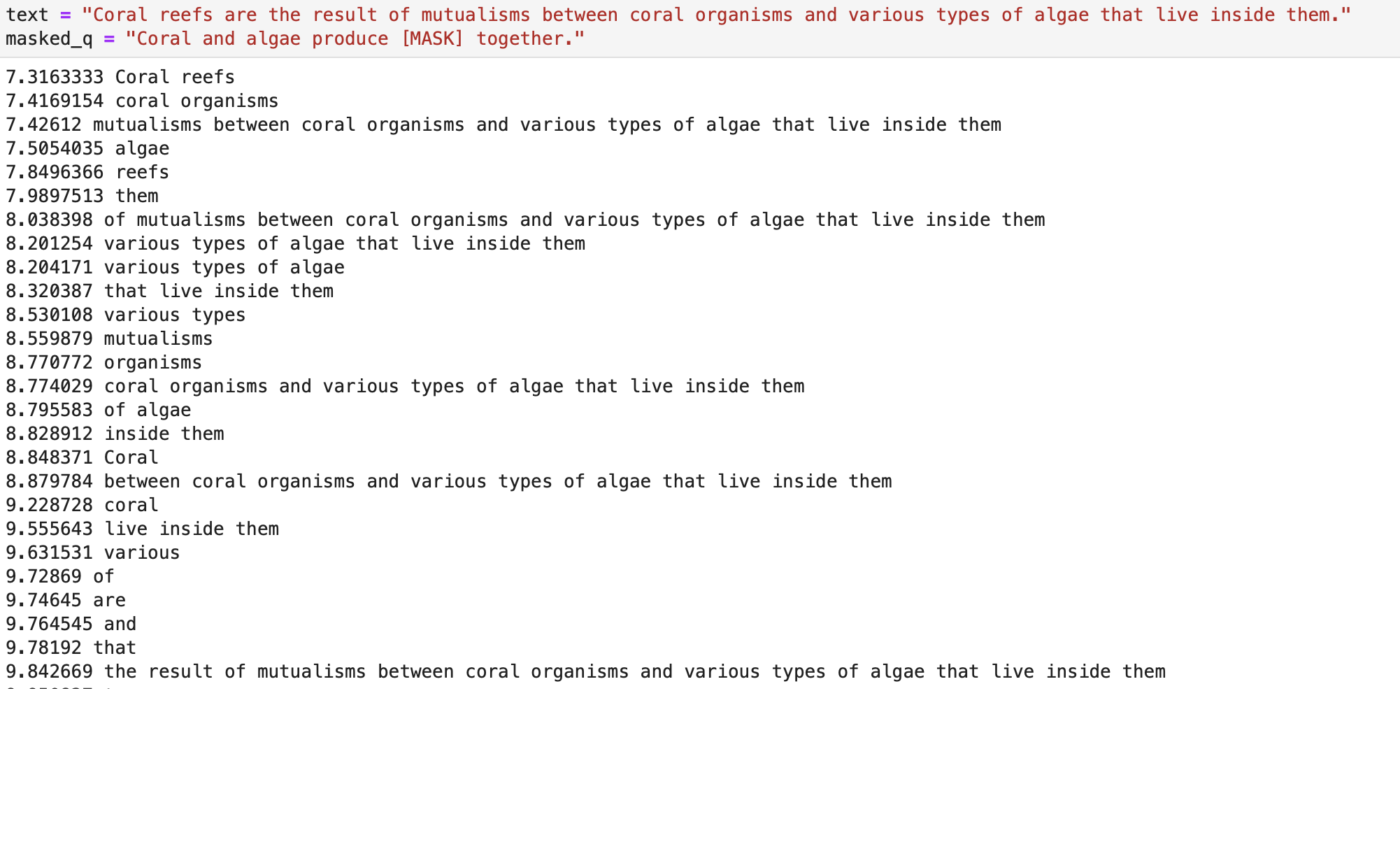
Example results
The following examples are (mostly) taken from the Stanford Question Answering dataset (SQuAD).







Future work
Overall we saw mixed results from the tests. As mentioned above, future work may involve training a BERT model on this exact task, instead of relying on an out-of-the-box BERT model, which will likely yield much better results.